孙正义再次加注OpenAI。
当地时间2月7日,据外媒援引知情人士的消息,日本软银集团(SBG)即将敲定400亿美元对OpenAI的首轮投资,投前估值为2600亿美元。
据报道,软银的首笔资金最快将于春季到位,全部资金将在未来12-24个月内分期支付。该笔融资规模将打破OpenAI上一轮创下的硅谷单轮融资纪录。本轮融资后,不仅OpenAI的投后估值将相较上一轮融资后翻倍,达到3000亿美元,软银也将超越微软,成为OpenAI的最大投资方。

当地时间2月3日,软银CEO孙正义与OpenAI CEO山姆·奥特曼会谈。
就在几天之前,软银刚刚与OpenAI达成协议,将在日本成立合资企业“SB OpenAI Japan”,共同打造名为“Cristal(水晶)”的人工智能产品,为企业提供服务。孙正义表示,软银每年将在OpenAI产品部署上投入30亿美元。
前述消息人士称,此次融资的部分资金预计将用于兑现OpenAI对“星际之门(Stargate)”项目的承诺。
“星际之门”启动,奥特曼“全球路演”
美国总统特朗普在1月21日宣布了“星际之门”项目,软银、OpenAI和美国甲骨文公司(Oracle)三家企业将投资5000亿美元,用于建设这一史上最大的AI基础设施投资项目。软银CEO孙正义将担任“星际之门”项目主席,软银承担项目的财务责任,OpenAI负责公司运营,并自主建设和管理数据中心。
据介绍,项目初始投资为1000亿美元,并计划在未来4年内扩展至5000亿美元,预计将为美国创造10万个就业岗位。
当地时间1月23日,OpenAI CEO山姆·奥特曼(Sam Altman)晒出“星际之门”在美国得克萨斯州首期工厂的视频,第一期已确定在美国得克萨斯州阿比林数据中心基地展开,计划打造10个数据中心。
当地时间2月6日,OpenAI表示正考虑在美国16个州建立数据中心园区,预计每个数据中心园区将创造数千个就业机会,包括建设和运营岗位。但根据最近的报道,“星际之门”在阿比林的首期数据中心只能创造57个就业机会。
除了日本,奥特曼近期还前往了韩国和印度。
2月4日,奥特曼现身韩国,与SK集团董事长会面,又和孙正义一起与三星电子董事长会谈。当天,OpenAI还宣布与韩国最大的社交应用运营商Kakao达成战略合作关系,双方计划共同开发面向韩国市场的AI产品。
奥特曼透露,OpenAI正在积极考虑投资并加入韩国的人工智能计算中心项目,并暗示韩国企业可能会参与“星际之门”项目。
2月5日,印度信息技术部长阿什维尼·维什瑙(Ashwini Vaishnaw)与奥特曼会面,讨论涉及GPU、模型和应用程序的AI战略。
当地时间2月7日,奥特曼又已现身德国,在柏林工业大学参与了AI专题活动。

当地时间2月7日,山姆·奥特曼现身柏林工业大学,
据悉,奥特曼此次“全球路演”还会前往法国、迪拜等地。
DeepSeek震惊硅谷,OpenAI还有“后手”?
OpenAI着急寻求合作和投资,恰逢来自中国的DeepSeek在硅谷引发轰动。
1月20日,中国AI初创公司深度求索推出开源大模型DeepSeek-R1,性能比肩OpenAI o1模型正式版,而训练成本或仅需约600万美元。
如此“物美价廉”,Meta、微软、OpenAI、Anthropic等公司纷纷关注跟进。投资界大佬们也都现身表态,方舟投资(ARK)CEO“木头姐”凯西·伍德表示DeepSeek证明了AI领域成功并不需要那么多钱,加速了成本崩溃;桥水基金创始人瑞·达利欧表示,中国在芯片上或许落后,却在应用上实现了领先,AI竞争比企业盈利更重要,但投资者对AI的狂热助长了美股的“泡沫”,其程度类似于千禧年的互联网泡沫……
奥特曼曾评价称,DeepSeek让OpenAI的领先优势将不会像前几年那么大了,并称个人认为在开源权重模型和研究成果的问题上,OpenAI已经站在了历史的错误一边,需要制定不同的开源策略。
不过,在1月27日的一次采访中,奥特曼表示,DeepSeek的“这种性能并不新颖,我们早已具备这一水平的模型,今后将持续开发更先进的模型”。
2月7日,OpenAI也公开了o3-mini大模型的思维链。不过,与DeepSeek不同,o3-mini的思维链文本并非大模型原始思维链,而是进行过“总结”。对此,奥特曼的解释是,OpenAI正努力整理原始的CoT(思维链)提升可读性,并在必要时提供翻译,尽量保持原始内容的忠实度。

OpenAI大模型o3-mini的思维链文本。
巨额融资和更多的合作方,不仅可以让OpenAI推进算力扩张、模型及智能体(agent)研发,也可以助力其在硬件方面的布局。
OpenAI自2024年底开始已在重组机器人部门,Meta增强现实(AR)眼镜团队前负责人凯特琳·卡利诺夫斯基(Caitlin Kalinowski)已经官宣加入并负责机器人和消费硬件业务。
今年1月末,OpenAI向美国专利商标局提交新的商标申请,涉及人形机器人、XR、智能手表、可穿戴设备等硬件设备。
奥特曼还曾在采访中透露,将与苹果前设计负责人乔尼·艾维(Jony Ive)创立的企业合作,推进开发AI终端,不过公开原型机尚需数年时间。
对于AI开发中不可或缺的芯片,奥特曼表示“公司正在自主研发”,但未透露具体细节。
值得一提的是,当地时间2月4日,OpenAI长期投资的美国机器人初创企业Figure的创始人布雷特·阿德科克(Brett Adcock)宣布将终止与OpenAI的合作。他表示Figure在完全自主研发的端到端机器人AI上已取得重大突破,并将在未来30天内展示一些从未在人形机器人上看到过的东西。
这像极了OpenAI曾与微软达成的协定——一旦达到AGI(通用人工智能)水平,就可以终止与微软的独家合作关系。
OpenAI究竟能否“遍地开花”?外界可以拭目以待。
今年春节,国产AI公司深度求索开发的大模型DeepSeek成为爆款,作为一款开源、免费的大模型,尽管还未实现盈利,但第一批用它“搞钱”的人已经出现了。
2月6日晚上,曾经广受关注的“AI卖课第一人”李一舟在自己直播间兜售创业课程时谈到DeepSeek,称背后有很多创业机会,“这个我就不方便多说了,非常值得大家去学习和使用。”
“如何用DeepSeek赚到100万”“DeepSeek带你躺着赚钱”......在社交媒体上,频频能看到教你如何用DeepSeek实现一夜暴富,在淘宝、闲鱼等平台上,不少商家打着“本地部署”的概念兜售DeepSeek接入教程,标价最高达到10万元,最低仅有0.01元。
澎湃新闻记者查询发现,某热门DeepSeek社区会员费为61元,总会员数超过3600人,在DeepSeek爆红的近一个月里,仅会员费收入就超过18万元。
对于各类利用DeepSeek牟利的投机者,6日晚间,DeepSeek官方发布声明:目前除DeepSeek官方用户交流微信群外,从未在国内其他平台设立任何群组,一切声称与DeepSeek官方群组有关的收费行为均系假冒。
利用“信息差”牟利
DeepSeek最大的特点就是是开源,而在多家电商平台上,有商家公然售卖可以免费下载的DeepSeek软件,并且不加掩饰地告诉记者:“卖的就是信息差。”
无论是元宇宙、Sora还是DeepSeek,每当新一波革命性技术迎来讨论,似乎“卖铲子”的人总是最先挣钱。据新榜数据显示,近7天内,在抖音、快手、B站、小红书、微博、微信等平台上,和DeepSeek相关的内容作品数至少在105万条,日均作品数超15万。
在付费知识社群“知识星球”上,记者搜索到超过百个DeepSeek相关社群,基本内容都是分享DeepSeek相关课程,会员收费从50元到200元不等。
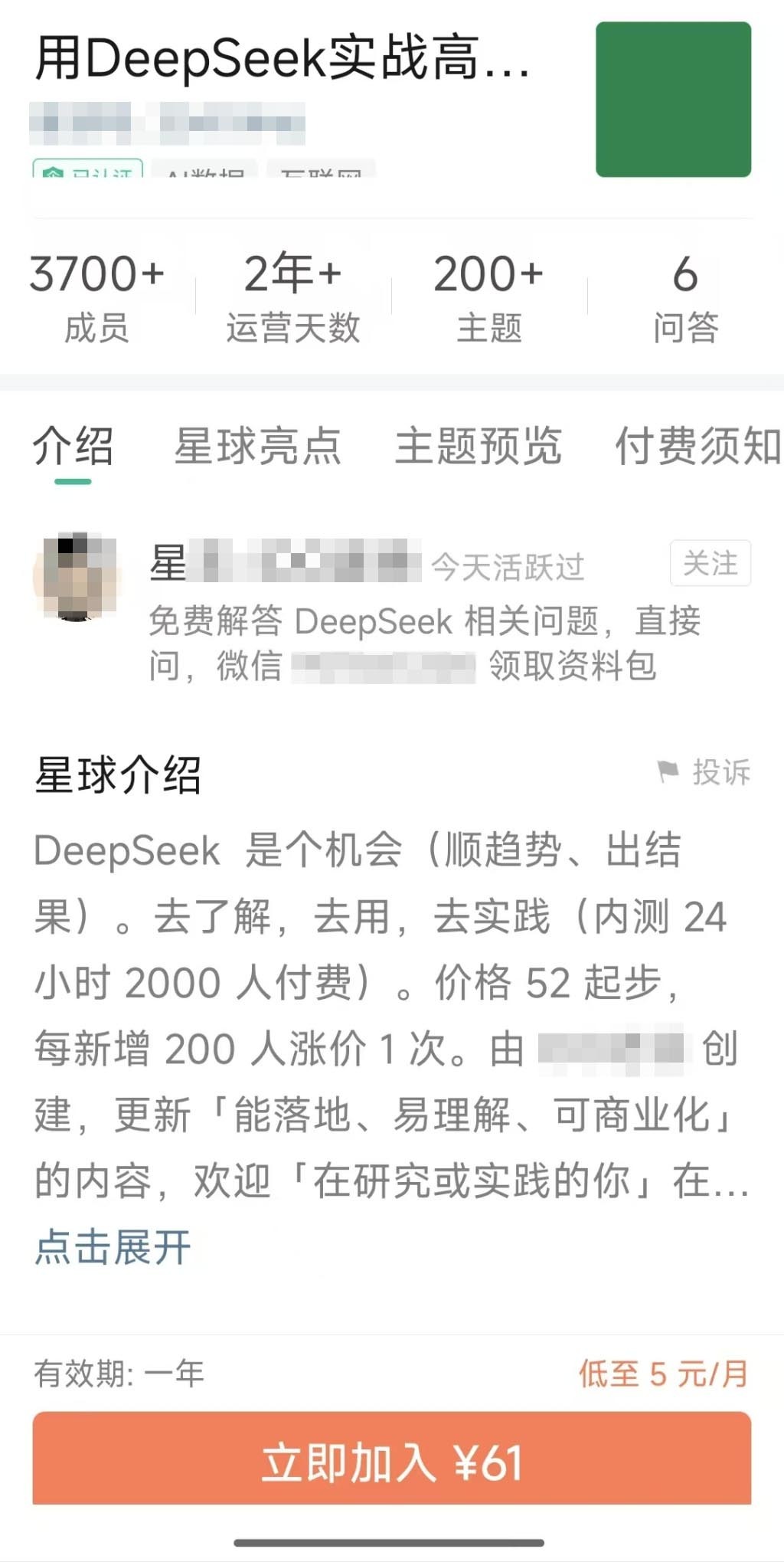
某热门DeepSeek社群收费
不少荐股博主还开发出DeepSeek的炒股功能,在抖音直播间里,记者看到,有博主宣传只要用同花顺等炒股软件接入DeepSeek,就能控制电脑全自动分析股票,在直播间下方还附上了教程和软件的购买链接。记者联系到了其中一位用DeepSeek分析股票的荐股博主,对方称自己已经被封号。
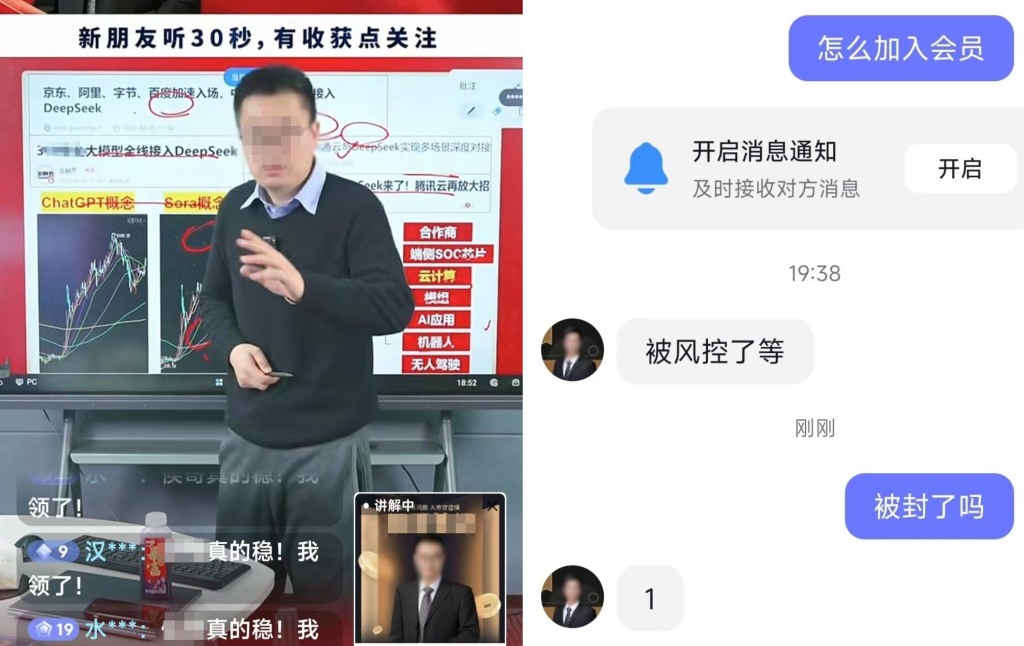
博主在抖音直播间宣传用DeepSeek炒股
除了传统的售卖AI培训课、AI社区付费等套路,售卖DeepSeek本地部署教程成为新的掘金方式,不少商家挂出5万元、10万元高价。
所谓的本地部署,意思是把DeepSeek模型下载到电脑上,然后用电脑的显卡进行推理。闲鱼上一位商家告诉记者,标价5万元是包含主机的价格:“DeepSeek对硬件要求很高,一般普通电脑根本跑不了完整版本。”
“本地部署,精细化AI”“API调用训练”“可以自行投喂数据”在平台上,关于本地部署DeepSeek的教程软件泛滥,从几分钱到几元钱、几十元价格不等,仅凭介绍很难分清有什么区别。
有商家告诉记者,这是因为不同价格售卖的版本不同,价格低廉的大多为蒸馏版DeepSeek,可以进行基础问答但没有推理能力,而满血版DeepSeek需要强大的算力支持,即便付费购买了软件,没有配套的硬件设施也无法运行。
这些商家行为显然就是利用DeepSeek可以本地部署的幌子,真正目的是销售硬件,但性价比对于一般用户而言却无法判断辨别。
AI概念火热,新兴职业涌现
售卖这些五花八门、标价混乱的本地部署课程和软件,是否涉嫌利用DeepSeek非法牟利?
记者查阅DeepSeek官方文件显示,由于是开源大模型,允许本地部署服务,但涉及到商业销售和牟利,就可能涉嫌触犯法律。协议显示,官方提供的模型和工具(如通过Ollama部署)遵循MIT开源协议,协议允许商业使用、修改和分发,但需保留版权声明并明确免责条款。
在遵守MIT开源协议的前提下,第三方提供本地部署技术支持或托管服务是允许的。但若涉及模型权重的商业化销售、未经授权的二次分发,或未履行开源协议义务,则可能构成侵权。
值得一提的是,除了利用DeepSeek赚钱,已经有不少掘金者涌入了AI赛道,例如AI画师、AI视频剪辑、AI文案创作等新兴职业如同雨后春笋一般出现。以某AI绘画社区为例,会员费用为565元,目前共有2万会员,以此初步推算,一年会员费收入就接近千万元。
有AI视频创作者表示,自己利用AI软件春节帮企业制作了以喜庆蛇年为主题的一些短视频,再配上喜庆的歌曲和文字,发布不久后就获得了几万的点击量,挣到了六位数的推广费。也有人通过做AI视频引流,进行橱窗带货,获得了超过8000元的佣金收入。
也有原影视团队转型做AI,以“自然风景+AI”“热门IP+城市地标+AI”的模式,利用AI生成脚本、图片、视频、配音、后期等流程产出成片,在半年内盈利约30万元。
还有人用AI生成文案、用AI作图等,有绘图作者提到,自己通过Midjourney和Stable Diffusion在春节生成了不少AI绘画作品,比如带有福字、舞狮、蛇年等图案的各类壁纸,非常受欢迎。有创业者靠定制AI头像和壁纸的业务,在春节期间收入超10万,“只要抓住机会,这一两年里就能积累巨额财富。”
“目前AI培训领域存在鱼龙混杂、良莠不齐的现象,部分机构缺乏资质,存在夸大培训效果、利用信息差收取暴利费用等情形。”华东政法大学竞争法研究中心执行主任翟巍向澎湃新闻记者表示,依据《反不正当竞争法》《消费者权益保护法》等法律法规,应当对DeepSeek培训领域予以规范和引导,以保障AI培训行业的健康有序发展。
对于突然涌现的大量AI新兴职业,翟巍认为,由于对人工智能投喂的语料(训练数据)可能本身存在侵犯版权、商业秘密或个人隐私情形,因此人工智能生成的作品可能出现衍生的侵犯版权、商业秘密或个人隐私后果。
此外,关于人工智能生成作品的法律属性和权益主体问题,现在缺乏明确的法律规定,这一方面导致利用人工智能生成作品的个人难以依据现有法律主张自身对这些作品享有财产、人格权益,另一方面也导致在人工智能作品侵犯他人权益的情形下,难以确定侵权责任的承担主体。
“AI(人工智能)的尽头是医疗。”“用更好的AI,守护人们的健康。”2025全球开发者先锋大会(GDC)第二天,2月22日下午,在“AI焕新,塑医疗未来”论坛上,这两句话被人们多次提起。AI正深刻地影响医疗行业:从医学影像的智能诊断到手术机器人辅助操作,到临床决策支持和医院管理……谁能领跑“AI+医疗”这一新赛道?

2025全球开发者先锋大会(GDC)第二天,在上海市徐汇区西岸艺术中心A馆召开的“AI焕新,塑医疗未来”论坛,会场边上围了一圈挤不进现场的人。
从上海交通大学医学院附属瑞金医院发布病理大模型,到上海市第六人民医院推出全球首台贴片式超声设备及AI识别技术,再到上海市建成集“算法-算力-数据”三位一体的医疗大数据训练设施,通过不断降低医疗AI技术门槛、加速产业集群与创新生态构建,上海正逐渐建设成为包括医疗人工智能在内的AI应用“高地”。这一战略优势的形成,源于上海独特的医教研资源禀赋——复旦大学、上海交通大学等顶尖学府不仅拥有实力雄厚的医学院及附属医院,更在医工交叉学科领域形成突破性创新链,持续产出具有国际影响力的前沿成果。
上海临床创新转化研究院(以下简称“临转院”)总裁段琦向澎湃科技表示,作为医疗人工智能产业的创新枢纽与赋能平台,临转院将加快技术攻关并孵化出更多高质量的医疗人工智能应用与产品,全面提升医疗行业效率与质量,缓解医疗资源供给不足的问题,创造更大的经济价值。
“上海是中国做垂类大模型(垂直领域大模型)及应用场景做得最好的城市之一。”22日,上海市人工智能行业协会副秘书长沈涛在主持圆桌讨论时说,而“AI+医疗”是其中最重要的行业之一。
先行者基因:政策引擎,生态筑基
早在2017年10月26日,上海市人民政府办公厅就印发《关于本市推动新一代人工智能发展的实施意见》的通知,提出利用认知计算和深度学习技术,提升诊疗辅助、健康管理和养老照护等服务能力。加强自主智能医疗机器人和医疗设备等在辅助病症诊断、影像分析、手术诊疗、精准医疗中的推广应用,促进医疗服务精准化。
随后,上海又先后出台了《加快推进上海人工智能高质量发展的实施办法》(沪经信技〔2018〕569号)、《关于建设人工智能上海高地构建一流创新生态的行动方案(2019-2021年)》(沪经信智〔2019〕707号)等政策文件,推动人工智能创新布局。此外,上海还设立人工智能创新发展专项资金,对人工智能产业领域的创新项目予以支持。
其中,医疗行业是上海加快推动人工智能垂直领域的规模化应用的六个重点行业之一。
“模型群”
上海市肺科医院副院长陶蓉表示,“我们研发了那么多医疗AI大模型,未来希望推广到更多医院去。”她认为,应该基于高质量的医疗数据和正确的标注,研发一个个基于单病种的专业的大模型,然后推广、落地、应用,反哺临床。
她介绍,上海市肺科医院目前已实现DeepSeek70b与671b模型本地化部署。在大模型研发方面,该院首先着力于AI医学影像辅助系统。“我们每天有4000多名患者拍CT,医生阅片、诊断的工作量非常大,非常辛苦。现在已经能够把筛查出来的内容整合到模板当中,快速生成文字的描述,进入报告中,大大提高了工作效率。”换句话说,CT影像检查不再积压,检查报告当天就能生成。
作为专科医院,在单病种AI模型方面,上海市肺科医院联合人工智能企业商汤科技进行本地化搭建智慧病理数智一体化平台,目前正在对数字病理切片进行标注和模型训练。

上海市肺科医院副院长陶蓉
此外,上海市肺科医院还研发了肺部智能手术规划系统。“(以前)影像片导入之后需要花2-4个小时,现在只要2-5分钟的时间就能够做三维的重建、手术的规划模拟等。”陶蓉说。
上海交通大学医学院附属瑞金医院-上海市数字医学创新中心专职副主任朱立峰介绍,瑞金医院研发的医疗AI大模型目前形成了“大模型群”,来“支撑”医生、服务患者,并“支撑”该院的医学教育以及医院的管理。
四天前,2月18日,上海交通大学医学院附属瑞金医院刚刚发布了一个病理大模型——RuiPath(瑞智)。
他介绍,一方面,瑞智是一个泛癌种的基础大模型,覆盖中国全癌种人数90%的癌种,并且完成了视觉和语言的跨层表征;此外,它还是一个推理大模型,具备深度思考能力,可以开展互动式病理诊断对话。该模型使用瑞金医院积累的100万张的WSI数字病理切片影像数据,包括对应的报告文本,完成训练。

上海交通大学医学院附属瑞金医院-上海市数字医学创新中心专职副主任朱立峰
此外,瑞金医院还研发了胸部影像大模型和医学文档大模型。
在“体检总检报告生成”落地应用场景中,相关大模型可以智能分析各项体检报告,自动识别高风险异常,提供个性化健康建议,大幅提高书写效率和质量。从2023年12月至今,已生成超过10万份报告;而在“电子病历生成”的应用中,根据患者入院后各项诊疗数据,智能识别异常情况、归纳总结诊疗过程,生成住院期间的医疗情况、病程与治疗情况、出院后用药与建议等完整病历。
“截至2月19日,全国至少14家三甲医院部署了国产AI大模型DeepSeek,包括上海市第四人民医院、上海市第六人民医院、昆山市第一人民医院等。”在演讲中,段琦援引相关统计数据称。
2024年,来自昆山市第一人民医院的“昆山模式:老年健康管理与生物医学大数据创新应用”成功入选江苏省首批“数据要素X”典型案例名录,成为当地医疗与人工智能深度融合的标杆。昆山市第一人民医院-昆山生物医学大数据创新应用实验室负责人陆轲表示,该医院通过将实验室自研模型与DeepSeek推理版底座深度整合,嵌入医院HIS(医院信息管理系统)、PACS(影像归档和通信系统)等系统,让“智慧底座+自研模型+院内数据”多模态协同。
上海六院:AI+硬件,打造全球领先的超声“识别”
上海市第六人民医院副院长郑元义表示,如果能把AI与硬件结合,协同创新,就能做到“非常强的创新”。

上海市第六人民医院副院长郑元义
为了提高安全性,规避X射线辐射带来的风险,他们团队希望设计出一款适用于妇女儿童的设备——手骨骼超声AI成像,用超声检查替代X射线检查,其识别的过程需要AI的帮助。上海六院通过与汕头超声公司、上海交大AI团队合作研发了手扫描超声设备,能把每根手指的骨骼识别出来,初步建立了“国际首创的、不依赖X线”的儿童骨龄超声AI预测新方法,正在加大临床研究样本。
郑元义介绍,他们还与华中科技大学联合研发了“肌骨超声断层成像”设备,能够识别出骨骼、神经、血管、肌肉等结构,通过“超声检测+AI识别”,有很多的临床应用。上海六院将他们研发的设备命名为UT(超声断层成像),以区别于CT(X线断层成像),目前“国际上还没有进入临床应用的同类产品”。他们还研发了可穿戴的贴片式超声,获得了国内第一张贴片式超声注册证,用“超声检测+AI识别”的方法可用于评价人体肌肉收缩力相关指标,目前已服务于国家重大航天项目。此外,这种设备与AI结合还可用于24小时无创、实时血压监测,已进入临床研究阶段。郑元义表示,这些创新设备的成功研发,离不开团队获得国家重点研发项目、上海市科委重点临床研究项目以及上海交大STAR成果转化项目等基金项目的资助。
上海临转院:以赋能医疗大健康产业为使命,面向行业全方位赋能
2024年7月,上海市政府在《关于加强本市临床研究体系和能力建设支持生物医药产业发展的实施意见》中指出,要持续推进临床研究成果转化,支持建立市场化、专业化的医学科技成果转化服务平台,促进高质量科研成果转化,并探索建立作价投资的转移转化创新模式和路径。
按照市委市政府的部署要求,2024年9月20日,由上海申康医院发展中心牵头组建的临转院正式成立,下设“临床研究与疾病队列建设、转移转化与投资、数据挖掘与人工智能”三大业务板块,服务于上海建设全球生物医药产业高地的战略目标规划。其中,数据挖掘与人工智能作为核心业务板块之一,围绕医疗人工智能技术研发、真实世界数据挖掘分析、高质量多模态医疗语料建设等方向开展工作,探索数据要素赋能医疗大健康与人工智能产业发展,助力上海医疗卫生健康产业整体的数字化、智慧化转型升级。

上海临床创新转化研究院总裁段琦表示,临转院将推动人工智能的规范化应用与产业赋能,孵化出更多高质量的医疗人工智能产品和技术。
临转院总裁段琦介绍,临转院将广泛合作积极开展医疗健康数据的应用创新,加快人工智能在生物医药、医疗器械、健康保险等领域的赋能与应用,深化跨界协同支撑产业发展。
技术应有的“温度”:人本医疗
22日的论坛上,医疗科技企业卫宁健康总裁王涛表示,“我们认为AI医疗的想象空间不仅仅是‘用AI辅助医生’,而是会以技术变革,重塑现有的医疗服务模式,例如预防性医疗、个性化医疗、整合性医疗等,从而为人民群众生命健康带来真正的福祉。”“我们相信,AI技术将为医疗普惠带来巨大帮助,有望通过AI进一步缩小城乡医疗差距,更好地促进医疗公平。”
从“以人为中心”理念出发,卫宁健康近年来打造了多款赋能医护人员的AI创新应用,包括本次论坛上发布的迭代版医疗大语言模型WiNGPT和AI产品WiNEX Copilot。“我们的初心不是以AI替代医生,而是增强医疗的能力和效率,让技术成为医生的伙伴。”卫宁健康副总裁兼CTO赵大平表示。
上海太翼睿景计算机科技有限公司董事长雷新刚在圆桌讨论中表示,“国家卫健委2024年发布了84个卫生健康行业人工智能应用场景,其实医疗健康的应用场景远远不止84个,我们的定位是,根据自己的能力和资源,深耕精神心理科、重症医学科、康复科,利用大模型的技术,做精做深,来赋能医院,提升效率和质量,改善患者的感受。”
“我们希望通过数据算法以及算力的加持,来回归我们整个医疗的本心。最终把冰冷的技术,化作温暖的服务,温暖患者,温暖医务人员。”陶蓉说。

“截至2月19日,全国至少14家三甲医院部署了国产AI大模型DeepSeek,包括上海市第四人民医院、上海市第六人民医院、昆山市第一人民医院等。”在演讲中,段琦援引相关统计数据称。
上海市肺科医院目前使用的大语言模型嵌入了患者风险预警,它结合检验影像等一系列的内容,对治疗过程中可能的风险进行预判、预警。而嵌入的知识库在医生在书写病历过程中,就可以进行内涵质控,如果发现存在缺陷,可以及时通知医生。
陶蓉介绍,该医院目前部署的智能输液监控区别于之前的称重输液监控,现在用的是固定摄像头进行图像采集,然后自动进行分析和计算,估算液量,进行决策和自动呼叫,准确率达到98%,从而减少了输液不良事件的发生,也降低了医疗成本。此外,该医院还部署了可以人机对话的AI机器人进行智能随访,显著提高了随访成功率。
开源是大模型发展的重要因素,DeepSeek的出圈进一步催化了模型开源。2月21日-23日,在上海举行的2025GDC全球开发者先锋大会上,多位嘉宾探讨模型开源趋势。开源到底对产业发展有哪些影响?开源是否会取代闭源?为什么说开源和闭源都或不可缺?看看嘉宾们都怎么说。
香港科技大学校董会主席、美国国家工程院外籍院士沈向洋:希望开源社区能贡献更多数据
沈向洋表示,互联网的出现令开源蓬勃发展,DeepSeek的火爆出圈是开源社区的胜利,将了不起的模型开源,就能让更多人在模型上做更多了不起的事。尽管当前闭源的份额仍然超过开源的份额,但接下来一两年将剧烈变化,平衡开源与闭源,引领未来。“大模型时代,开源并没有像以往那么多、那么快,我想,通过上海的努力,我相信开源这件事情会越做越好。中国的团队、上海的团队一定会引领开源潮流。”他也呼吁开源数据,“我希望开源社区能贡献更多数据,在新的范式里,大家一起有更大的进步。”
密度科技有限公司CTO刘益东:开源已成为不可逆转的潮流
刘益东表示,开源为行业生态注入活力,开源一定是潮流。DeepSeek证明开源是大势所趋,开源也一定能够带来产业欣欣向荣、爆发式增长的路径。国内大公司逐步加入开源行列,正是因为开源能够促进生态繁荣,进而反哺技术研发和应用场景拓展。开源还能带动产业上下游协同发展,形成良性循环。过去一些企业会开源部分模型参数,同时保留更优参数用于闭源服务。然而,当前趋势表明,无论是国内还是国外,开源已成为不可逆转的潮流,即便是曾经持保守态度的企业也不得不顺应这一趋势。
Linux基金会金融科技开源基金会技术监督委员会委员、前任全球董事安德鲁·艾肯:开源透明对AI至关重要
Linux基金会金融科技开源基金会技术监督委员会委员、前任全球董事安德鲁·艾肯表示,开源透明对AI发展至关重要。开源将提升社区凝聚力,在降低成本的同时提高AI技术使用率。开源也将提升产业信任度。未来AI企业需要在盈利性和商业价值上找到新的平衡点。
首个AI安全研究员朱小虎:开源项目商业化基本规则
首个AI安全研究员朱小虎介绍,开源社区或开源项目的商业化通常遵循一些基本规则:基于开源项目,企业可以开发针对特定领域的商业化产品或进行优化,并通过销售或寻找客户实现盈利。然而,开源对企业仍有一定门槛,其研发团队必须具备一定实力。目前一些企业虽在推动开源,但研发能力不足,可能仍需购买研发阶段的产品以满足需求。
星环科技副总裁杨一帆:开源叠加企业自身业务“护城河”是热点
星环科技(688031.SH)副总裁杨一帆表示,DeepSeek为AI开源“打样”,对人工智能行业从业者而言,开源叠加企业自身业务“护城河”,结合对场景、数据的理解,是未来的发展热点。
Hugging Face工程师王铁震:开源模型是工具,闭源模型是产品
王铁震表示,开源模型给了其他开发者微调的权利,开发者拿到一个基础模型后,可以通过模型后训练的方式让模型进化,模型“吃”到专有数据,可以变得更聪明,甚至可以蒸馏成更小的模型,降低服务部署成本。
但王铁震也表示,开源模型是工具,闭源模型是产品。“工具有些地方有棱角,拿的时候可能伤手。”王铁震表示,相对于只需调用API的闭源模型,要在公司内部把开源模型利用起来,需要配备一个技术团队,“开源模型首先要有自己的机房,要在网上申请一个服务器,要部署,需要知道怎么动态调整用户需求等等。”因此要客观看待开闭源的优劣势。
“最早,大语言模型火起来完全是由闭源模型带起来的,在ChatGPT起来之前已经有很多开源模型,但正是因为开源模型有本质的不足,不方便用,很多人看不到这个领域的进展,直到ChatGPT把英文模型拿出来,大家用了都说好,才引起了社会广泛关注。”王铁震认为,DeepSeek爆火并不仅仅是因为DeepSeek是开源模型,DeepSeek推出R1模型不久后就在全球上线APP,“如果没有DeepSeek方便易用的APP,只靠传统模型,是没有办法获取现在的影响力的。因为普通人用不起来,我们需要有更多更好的方式让普通人也能把模型用起来。”

野外作业现场
记者近日从中国第41次南极考察队获悉,为深入开展东南极拉斯曼丘陵地区冰下地质环境研究,在中国第40次南极考察期间,吉林大学和中国地质大学(北京)联合俄罗斯海洋与地质矿产资源科学研究所组成联合科研小组,在中山站以南约25千米处,利用我国自主研发的新型铠装电缆悬吊式电动机械深冰及冰下基岩取芯钻机(IBED)成功钻穿了545米厚的冰层及冰岩夹层,获取了连续冰芯样品和0.48米的基岩样品。

中俄科研小组
在第41次南极考察期间,中俄科研小组利用自主研发的测井仪器开展了钻孔摄像,获取了完整的冰川内部温度剖面,测量了钻孔倾角和方位角,同时对钻孔缩径过程开展了持续观测,获取了重要的原位冰川运动参数。此外,中俄科研小组还从钻孔内回收钻井液约7立方米,践行了环境保护的理念。

测井仪
这是我国首次在南极冰盖基于已有钻孔开展测井作业,获取了钻孔温度、倾角、方位角以及钻孔直径变化等关键参数,从而为探明东南极伊丽莎白公主地末端冰盖底部地热通量及其动力学演化机制奠定了基础,为揭示未来气候变化背景下的南极冰盖演化规律提供了重要依据。
拉斯曼丘陵地区位于伊丽莎白公主地冰盖末端,是东南极冰盖重要的溢流区之一。冰下地质环境是影响冰盖运动的重要因素,探明拉斯曼丘陵地区冰下地质环境对揭示东南极伊丽莎白公主地末端冰盖的动力学演化机制和物质平衡特征具有重要意义。
新模型周周见,Anthropic前脚推出混合推理模型Claude 3.7 Sonnet,OpenAI立马打出GPT-4.5这张牌。当地时间2月27日,OpenAI推出GPT-4.5,其追随用户意图的能力更强,“情商”更高。OpenAI CEO山姆·奥特曼将其形容为“是一种不同的智慧”,有一种他从未感受过的魔力。
虽然GPT-4.5作为一款非推理模型展示了在预训练进一步扩展后的能力提升,包括更高的准确性和更少的幻觉。但值得关注的是,在DeepSeek掀起开源潮和降价潮后,显然海外市场并没有被“卷”到,这次的GPT-4.5定价堪称“非常贵”,导致很多人感叹“一般人可用不起”。但从另一方面来看,中国科技企业开拓海外市场的必要性好像更大了。
“情商”更高,更懂暗示
据了解,GPT-4.5在扩展预训练和后训练规模上迈出一步,OpenAI通过扩展无监督学习和推理两个互补范式来提升人工智能的能力。扩展推理让模型在做出反应之前进行思考并产生一系列思维链,从而能够解决复杂逻辑问题。无监督学习提高了世界模型的准确性和直觉,GPT‑4.5提高了识别模式、建立联系和无需推理就能产生创造性见解的能力。
OpenAI表示,与OpenAI o1和OpenAI o3‑mini模型相比,GPT-4.5是一个更通用、天生更智能的模型。早期测试表明,与GPT‑4.5交互更自然。GPT‑4.5更广泛的知识基础、更强的追随用户意图能力和更高的“情商”,使它在提高写作、编程和解决实际问题等任务上有效。GPT‑4.5能更好地理解人类的意思,并以更细微的差别和“情商”来解释微妙的暗示或隐含的期望。
快思慢想研究院院长、原商汤智能产业研究院创始院长田丰表示,GPT-4.5的推出,印证了美国大模型继续走“大力出奇迹”的尺度定律路线,算力、数据、模型都是顶级配置,以更大的算力、更多的数据,训练出效果更好的模型,“GPT‑4.5的预训练阶段算力非常大,用了10倍的算力来做训练。”
“神仙”按月打架,重视技术储备
“今年大模型会出现你追我赶的节奏,OpenAI现在采取的策略像是 ‘领先半步’。”田丰表示。
在GPT-4.5推出前,OpenAI内部至少在迭代两个模型版本,即针对GPT-4.5和GPT-5进行测试、工程优化、产品化对齐等。“OpenAI有资金、人力、算力做双版本的储备,其他公司要跟上节奏,也必须做到。”他表示,在当前竞争周期越来越长的情况下,无论是国外的Anthropic,还是国内的DeepSeek,都需要有更多技术储备投入。
“头部大模型公司按季度更新模型版本,最慢100天,短的话30天,‘神仙打架’已经按月来打,一个季度就是一场巡回赛了。如果跟不上这个节奏,就要在产业链上找到自己的优势。”田丰表示,“大模型厂家如果不能每一两个月推出一个新版本,可能会憋大招,憋三五个月憋出一个好版本追上现在的大模型也是可以的。”
他认为,当前最值得关注的国外大模型是OpenAI的GPT-4.5、Anthropic的Claude 3.5、马斯克旗下AI公司xAI的Grok 3,尤其是三者间的逻辑推理能力对比更有价值。其中,Anthropic日前推出的混合推理模型Claude 3.7 Sonnet具有“系统一”和“系统二”两套系统,既可以快速回答用户问题,也可以针对复杂问题启动“系统二”的深度思考,思考时间会更长,就像人类一样。从这个角度看,Claude 3.7 Sonnet在架构的双系统层面具有一定的领先性和启发意义,“在数据和算力遇到瓶颈时,会把创新集中在模型架构层面,探索方法上的创新、工程化的创新、架构上的创新。”
田丰表示,GPT-4.5等模型将加速补全基础模型通用知识领域,增强复杂推理质量和情绪感知,基础模型负责高水平通用能力,AI应用负责行业逻辑。Grok3会在空间智能领域发力,加速具身智能体的“ChatGPT时刻”到来。垂直领域的专业模型也会成为中国大模型的竞技场,中国在机器人产量、使用规模方面更有优势。
庞大但昂贵
在对GPT4.5的性能给出了高度评价的同时,山姆·奥特曼也表示这是一个“庞大且昂贵”的模型。
据悉,调用GPT-4.5的API目前的输入价格为75美元/百万token,输出价格为150美元/百万token,不仅高于GPT以往的模型,也高于市场其他模型。以Claude 3.7为例,调用其API,输入百万token的收费为3美元,输出则为15美元。
跟国内模型更是不能比,DeepSeek-V3最近给出了错峰优惠政策,在凌晨时段,调用DeepSeek-V3的API输入百万token只需要0.25元,即便是非优惠时段也不过是0.5元;输出百万token的优惠价格是4元,标准时段价格为8元,定价均为人民币。
在业内人士看来,OpenAI的定价之所以如此之贵,一方面是其算力成本真的很高,另一方面也说海外市场和国内市场的定价策略遵循了不一样的逻辑,OpenAI仍然可以依赖技术优势获得更高的溢价。
田丰表示,OpenAI目前也面临GPU不够用的难题,GPT‑4.5推理成本高、算力开支大,导致用户使用昂贵,难以全民推广和使用。
OpenAI CEO山姆·奥特曼在社交媒体坦言,“我们真的很想同时为Pro用户和Plus用户推出,但我们已经发展得很快了,GPU也用完了。我们将在下周增加数以万计的GPU,向Plus用户推出服务。”ChatGPT Pro的月费是200美元。GPT‑4.5目前不支持ChatGPT中的语音模式、视频和屏幕共享等多模式功能。
Hugging Face工程师王铁震认为,OpenAI的定价策略之所以没有被DeepSeek“卷”到,是因为国内市场和海外市场原本就是不一样的定价策略。另有大模型从业人士认为,OpenAI仍然走的是“高服务定价-高企业估值”的业务逻辑,“追求技术快人一步,然后享受技术溢价”。
田丰认为,相对于美国企业的“大力出奇迹”,国内目前的大模型路线是以极致性价比实现更好的模型效果,“两边走得会越来越不一样,但最终都会拉到一个竞技场上去PK。”
在王铁震看来,国内市场“卷价格”已经遍布各行各业,相比之下,海外市场享有更高的利润,海外市场能够接受技术带来的溢价,这也是近年来中国企业集体出海的一个重要动力,但中国大模型企业要想走入海外市场,会面临和中国电动车等其他行业出海一样的挑战,这些挑战将不止于价格、技术和性能。
我国科学家近期取得一项研究成果,能够让动态无线充电更高效。其未来应用有望让无人机边飞边充电。相关成果近日发表于国际学术期刊《自然·通讯》。
西安电子科技大学电子工程学院李龙教授课题组在无线能量传输和无线定位领域取得突破性进展,构建了一种基于双频超表面的无线传能、感知定位与通信一体化原型系统,实现了自适应追踪的无线能量传输。在这一系统中,超表面不仅实现了精确的目标定位,还能根据实时变化的环境和目标,进行灵活的能量聚焦,实现跟踪式隔空输能。
与传统的无线充电方式相比,该技术具有显著的优势:能够支持多个终端设备在移动过程中进行高效的非接触式无线充电,例如运动中的无人机、智能机器人等,为其提供稳定、高效的电力供应。
据悉,该论文成果以西安电子科技大学为第一单位发表,电子工程学院博士生夏得校为论文第一作者,李龙教授和东南大学崔铁军院士为共同通讯作者。
2月28日,国家重大科技基础设施“冷泉生态系统研究装置”在广州市全面启动建设。该设施由中国科学院南海海洋研究所牵头申报并承担建设,项目包含“海底实验室分总体”“保真模拟分总体”“保障支撑分总体”三部分。这也是世界首个2000米级坐底式可载人长期驻留的深海实验室。
冷泉装置采用“样地实验+陆地模拟,海陆协同、时空互换”的设计思想,计划用5年的时间,建设面向冷泉生态系统的深海载人驻守型海底实验室与陆基保真模拟设施相融合的国际领先研究装置,支撑冷泉生态系统发育、化能合成生物演替和甲烷物态演化及其环境效应研究。冷泉装置建成后,将为探索深海极端环境下的生命起源及可燃冰等深海资源的绿色开发等前沿基础研究和高新技术研发提供先进的平台支撑,成为我国在深海科学研究领域迈出的关键一步,服务“海洋强国”战略及“双碳”目标。

“冷泉”是指海底之下的甲烷、硫化氢和二氧化碳等气体在地质结构或压力变化驱动下,溢出海底进入海水的活动。而冷泉生态系统是指海洋生物利用海底冷泉渗出的化学物质为能源进行化能合成,发育成海底黑暗世界里独特的生态系统,具有黑暗、高压、低氧等理化特征,以可燃冰分解的甲烷为生源要素,通过化能合成作用而生生不息,被誉为“深海绿洲”。冷泉生态系统承载着地球深部碳循环的密码,是研究极端环境生命适应机制、探索新型生物资源的战略要地。开展冷泉生态系统研究是可燃冰等深海资源绿色开发与深海科学研究的最佳切入点。冷泉装置将为冷泉生态系统的研究提供全新的视角和技术手段,加速相关领域的科研进展。

计划用5年的时间,建成国际首个2000米级坐底式深海载人驻留实验室
冷泉装置总建设计划用5年的时间,建成国际首个2000米级坐底式深海载人驻留实验室,这也是世界首个面向海底冷泉系统的大科学装置,建成后将促进冷泉发育机制、极端生命演化过程、可燃冰的生态效应研究等海洋科学跨越式发展,推动深远海科技进步。
今天(12月26日),我国自主设计建造的深远海多功能科学考察及文物考古船“探索三号”在广州南沙正式交付启航。“探索三号”是我国首艘具有覆盖全球深远海探测并具备冰区载人深潜支持能力的综合科考船。

“探索三号”船长约104米、排水量约10000吨,最大航速16节、艏艉双向破冰、续航力15000海里、载员80人。首次完成了全系列极地作业科考操控设备及国内最大水密科考月池系统装备、冰区深海声学探测、通信及定位装备,船舶动力定位系统等国产化技术的攻关和搭载。

在研建过程中,各研究机构、企业和高校等通过对关键核心技术集智攻关,突破了冰区船舶关键设计技术、冰载荷下高精动力定位控制技术、智能船舶控制技术等多项关键技术的垄断瓶颈,使我国载人深潜能力从全海深拓展到全海域。
记者从中国科学院空天信息创新研究院获悉,该院方广有研究员领导的月球与火星探测雷达研究团队发现,位于火星北半球乌托邦平原南部祝融号着陆区的地下10至35米深处存在多层倾斜沉积结构。这些地质特征与地球海岸沉积物高度相似,为火星中低纬度地区曾存在古代海洋提供了迄今最直接的地下证据。该成果北京时间2025年2月25日在《美国国家科学院院刊》(PNAS)上发表。
火星因其与地球相似的地质特征、季节性变化和昼夜节律而被科学家视为人类星际移民的首选目标。过去数十年,人类对火星的探测已取得诸多里程碑成果,但这些发现大多集中在环境极端寒冷的火星高纬度或极地区域,并且关于火星北部低地是否曾存在浩瀚海洋的争论始终存在,这使得获取火星古海洋的直接证据至关重要。
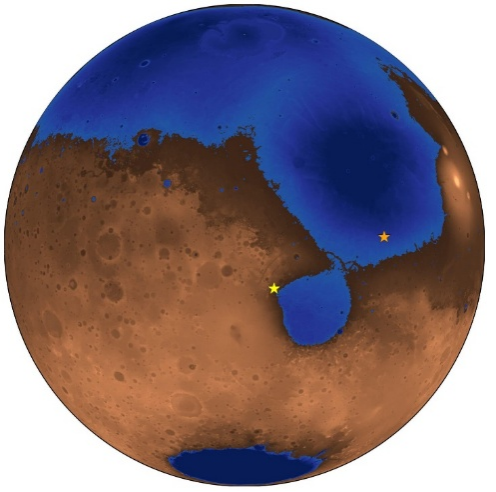
火星36亿年前的假想图。蓝色区域显示了现已消失的Deuteronilus古海洋和海岸线。橙色星标表示中国祝融号火星车的着陆点,黄色星标是NASA毅力号火星车的着陆点(图片来源: Robert Citron)
中国首辆火星车祝融号于2021年5月15日着陆于乌托邦平原南部,搭载有中国科学院空天信息创新研究院研制的火星次表层穿透雷达,用于探测地下结构和可能存在的水冰。祝融号行驶的路线位于前人提出可能存在的古海洋海岸线以北约280千米处,海拔比该海岸线低约500米。
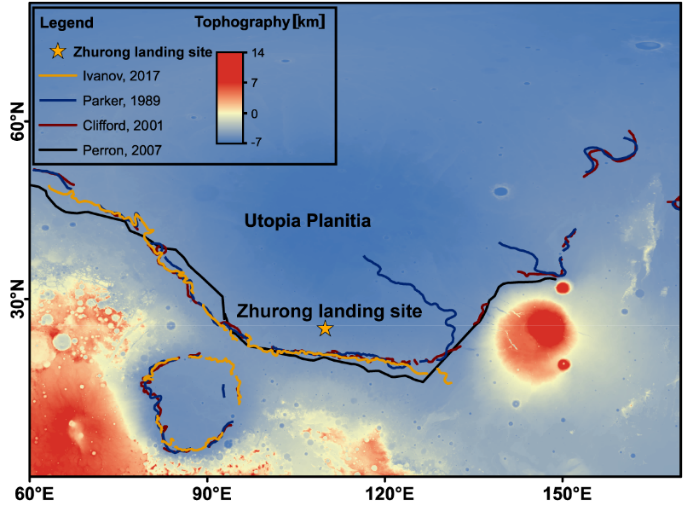
乌托邦平原地图、祝融号火星车着陆点和四条可能的古海岸线
研究团队通过分析祝融号雷达低频通道实测数据,在火星车沿途地表以下10至35米深度范围内识别出76个地下倾斜反射体。这些发射体空间分布广泛且均匀,覆盖范围超过1.3千米,所有反射体均呈现向北方低地方向倾斜的特征,倾角介于6°至20°之间、平均倾角为14.5°,且在相同位置的不同深度可观测到多个平行分布的反射体。这些层理结构与地球沿海沉积物的雷达成像结果十分相似,其一致性和物理特性排除了风成沙堆、熔岩管道或河流冲积等其他成因。这些沉积物的大规模存在表明,风浪驱动的沿岸输送为海岸线提供了稳定的泥沙净流入,并形成了海岸线前积层,这种结构只有在持久稳定的大型水体环境中才能形成,而非仅仅是局部和短暂的融水现象。
这项研究不仅提供了火星北部平原曾存在古代海洋的关键地下证据,还揭示了火星曾经经历过长期温暖湿润的气候期,这意味着火星曾长期维持适宜液态水存在的温度和气压条件。此外,研究发现的海岸线沉积物电介质特性与地球上由细砂和中砂颗粒的介电常数一致,这也进一步证实了其海洋沉积物的性质。
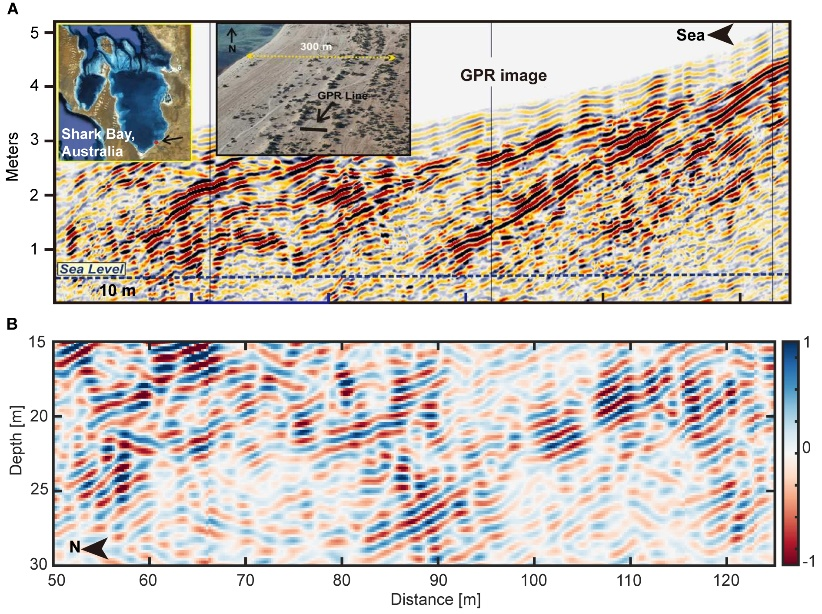
火星上探测到的倾斜反射与地球海洋沉积物的对比 (A) 澳大利亚Shark Bay滨海沉积物的探地雷达图像;(B) 祝融号火星次表层穿透雷达低频通道雷达剖面图
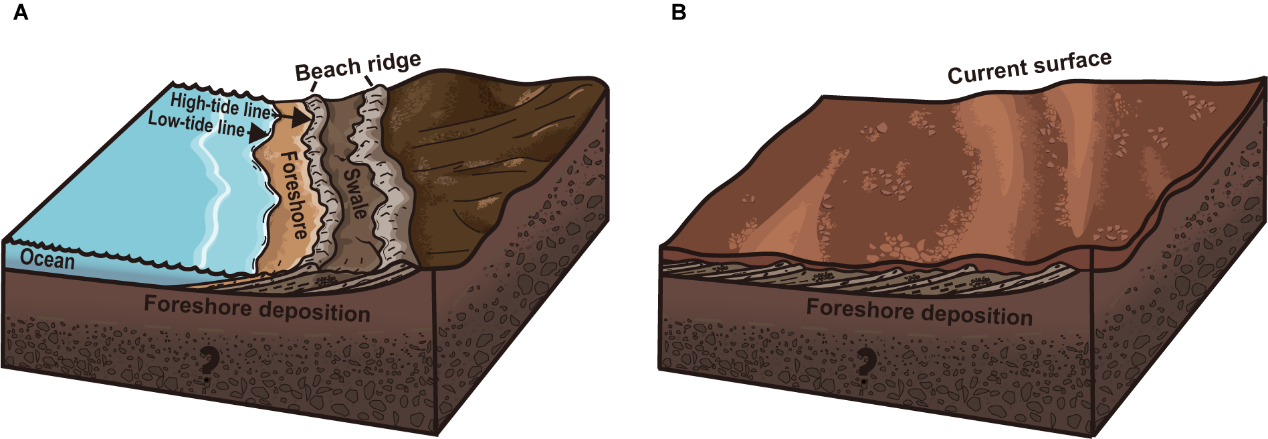
祝融号着陆点倾斜沉积结构形成过程的示意图(A) 潮汐沉积作用下形成的分层结构;(B) 随着古代海岸线后退,液态水消失,沉积作用停止。随后长期物理和化学风化改变了岩石和矿物的性质,导致火星表面层的形成。因此,沉积物被当前的火星表面土壤覆盖
此次发现的最大意义,在于将火星液态水的证据从火星人迹罕至的极地地区,扩展到了更适合人类活动的中低纬度地区,证实了火星曾经是宜居的。如果这一区域曾存在海洋,那么随着气候变迁,大量水分可能以地下冰的形式被封存,为未来火星基地的水资源利用提供了可能,也将大大降低火星基地的建设和维护成本。此外,这些古海洋沉积物保存了火星气候变化的历史记录,研究这些沉积物可以帮助我们理解火星如何从温暖湿润转变为寒冷干燥,进而指导人类如何改造火星环境,实现火星的长期可持续居住。